One of the biggest advantages of parametric modeling in Grasshopper, compared to manual modeling in Rhino, is the ability to create and modify entire lists of objects simultaneously. However, it can get complicated when processing a list of objects with a list of individual values. To get consistent and predictable results we need to know how the objects of the two input lists are paired. This is where data matching comes in. In this guide we’ll cover the Grasshopper’s primary data matching algorithm: the Longest List principle, as well additional ways of matching two lists.
Introduction to Data Matching
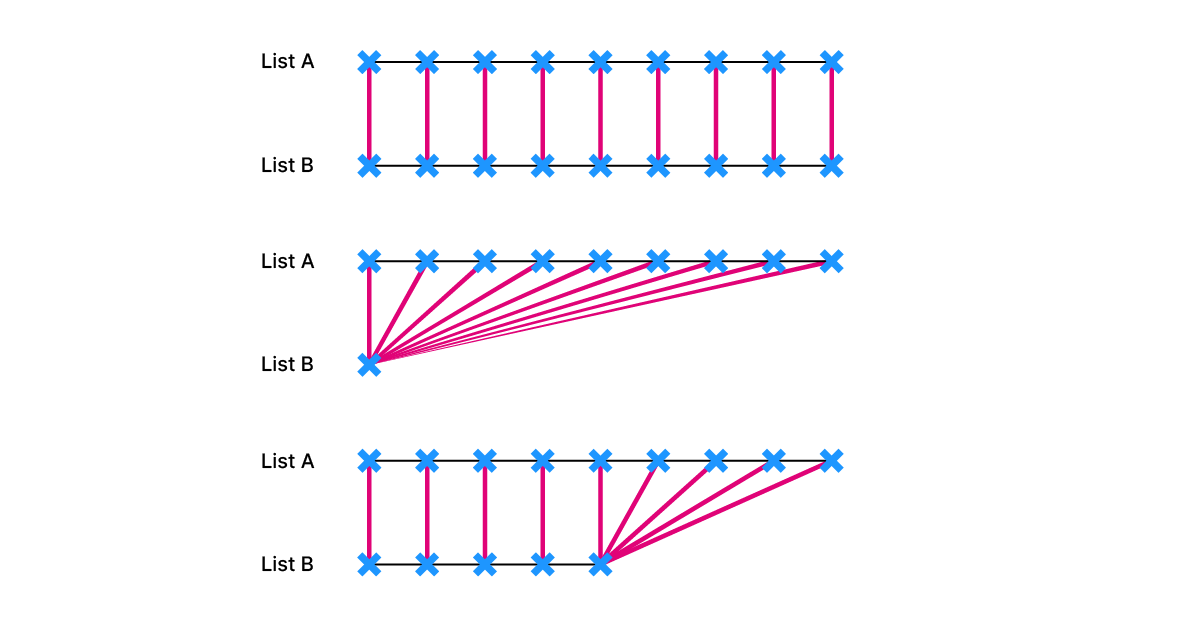
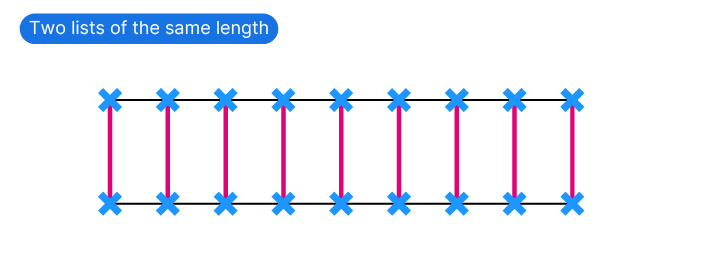
Let’s start with a simple scenario: you have two lists with the same number of points, and you want to connect them with a line. Assuming both lists are ordered and aligned, pairing the points is straightforward: the first point in the first list connects to the first point in the second list, the second point to the second, and so on.
Similarly, if you have a list of points and you want to connect them to one other point, the result seems obvious.

But what happens when dealing with lists of different lengths?
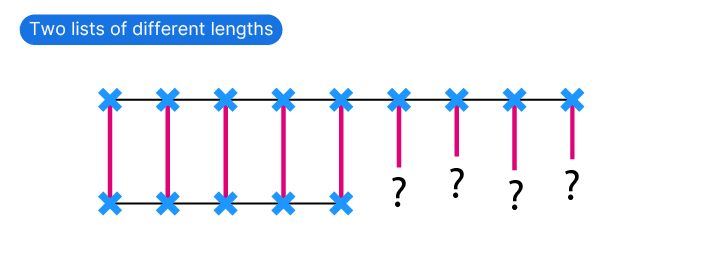
This is where data matching comes in.
Data Matching Explained
When handling two lists of different lengths, we need a strategy to manage the mismatch. While there are several options, Grasshopper is built around one specific data matching approach: the Longest List principle.
The Longest List Principle
The Longest List principle ensures that when two lists of different lengths are matched, the longer list is prioritized. Grasshopper pairs items from both lists until one list runs out, then repeats the last item of the shorter list to match the remaining items of the longer list.
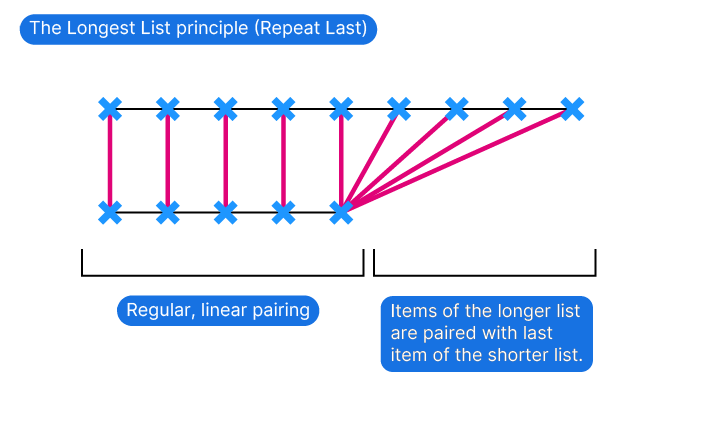
Example:
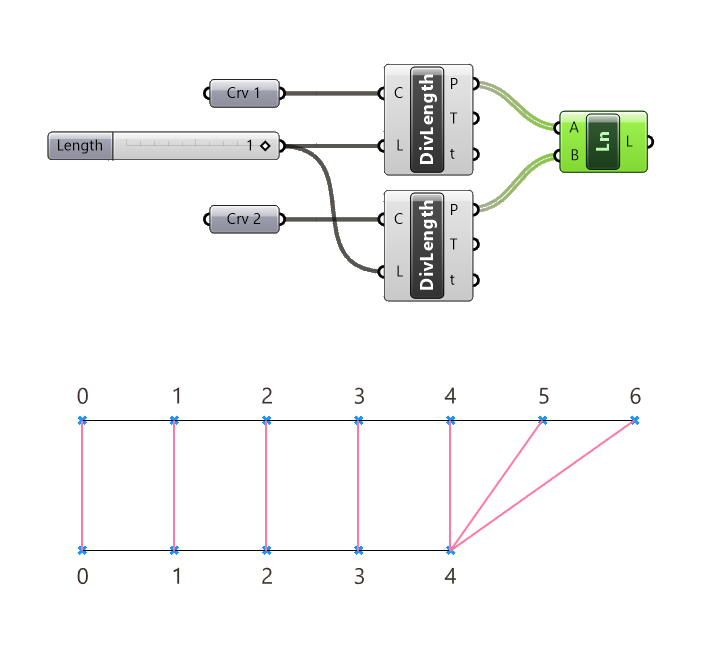
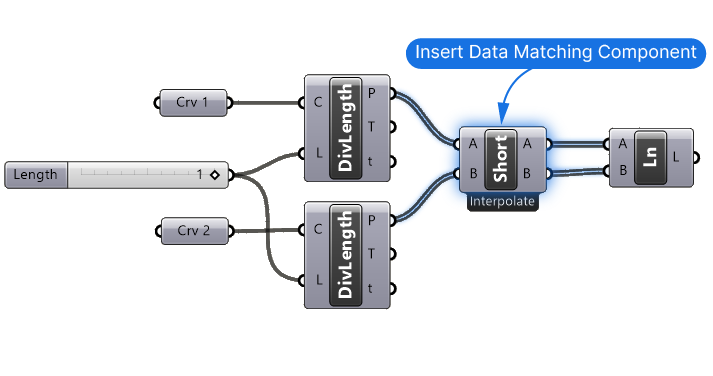
Imagine you are dividing two referenced curves of different lengths by a length resulting in two lists of points of different lengths. A Line component draws a line between the resulting points.
Because of Grasshopper’s built-in Longest List approach the excess points from the longer list will pair with the last item of the shorter list.
Where the Longest List principle apply?
The beauty of the Longest List principle is its universal application. Every Grasshopper component that requires two inputs follows this data matching approach. Even when lists are of equal length, the principle is at work but doesn’t require repetition. In cases where one list has only a single value, that value is repeated for all items in the other list.
And it doesn’t stop there!
Longest List at the Data Branch Level
The Longest List principle also applies to data branches. If you have one data stream with six branches and another with three, the contents of the last branch in the shorter data tree will be duplicated to match the branches in the longer tree.
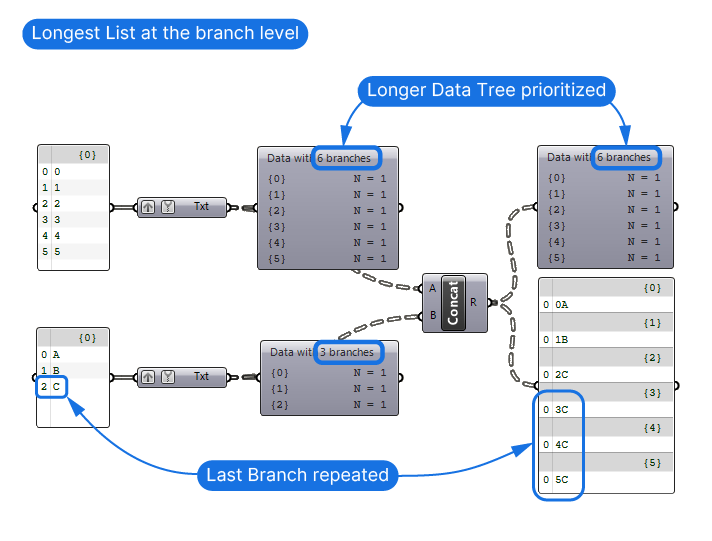
As you can see, understanding this simple principle can help understand how Grasshopper handles and pairs data streams.
More Data Matching Options: Longest List, Shortest List and Cross-reference Explained
While the Longest List principle is default in Grasshopper, sometimes you need different data matching methods. Grasshopper offers three main components for this: Longest List, Shortest List, and Cross-reference.
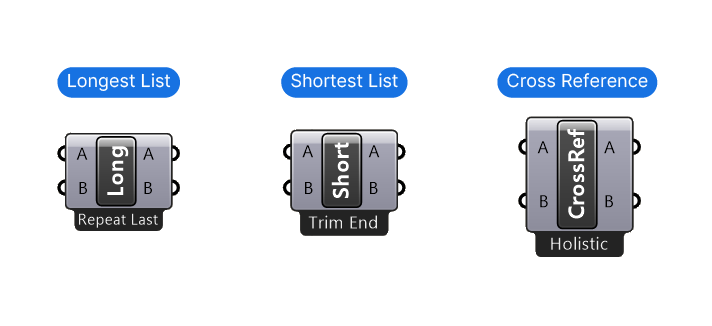
You can find these components in the ‘Sets‘ component tab, at the bottom of the ‘List‘ group.
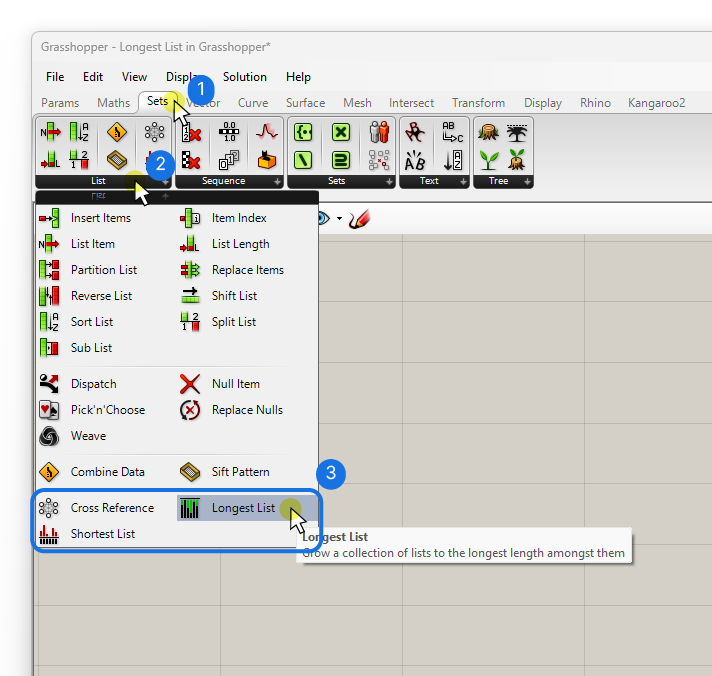
How to Use These Components
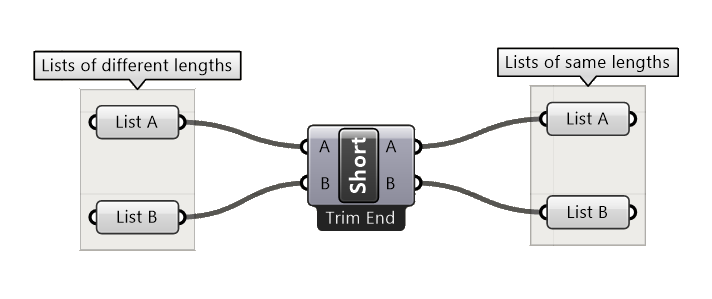
Each component has two inputs and outputs (A and B). The components adjust the shorter list to match the longer one based on the chosen method and provide matched lists ready for further use.
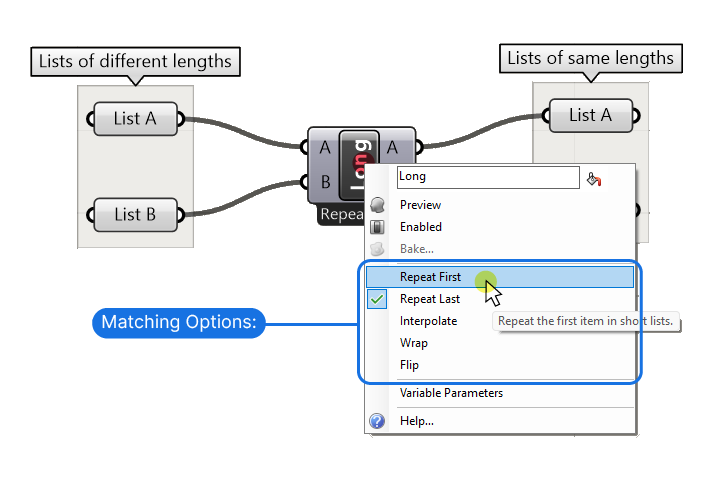
The Longest List, Shortest List and Cross-Reference components each have a subset of options that we can access by right-clicking on the component. In the popup menu we find the additional data matching modes.
To use these components, simply insert them right before the component that requires the matched data.
Next, let’s go through all the data matching options:
Longest List Data Matching Modes
As we’ve discussed the Longest List approach is used throughout all Grasshopper components by default. But there are many ways to prioritize the longer list, and to duplicate the last item of the shorter list is just one of them.
Here are the 5 options we can choose from.
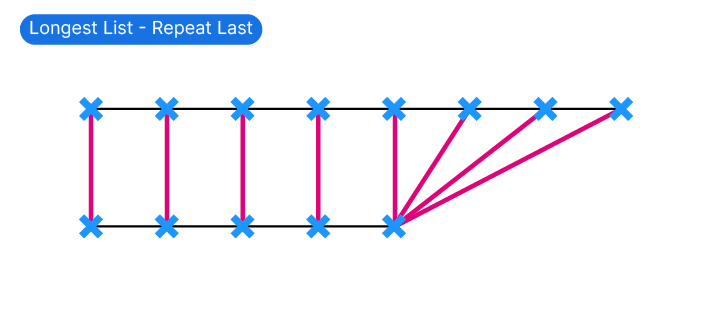
Repeat Last
The Longest List’s Repeat Last mode is Grasshopper’s default data matching algorithm: it prioritizes the longer list and repeats the last item of the shorter list until all items of the longer list are paired.
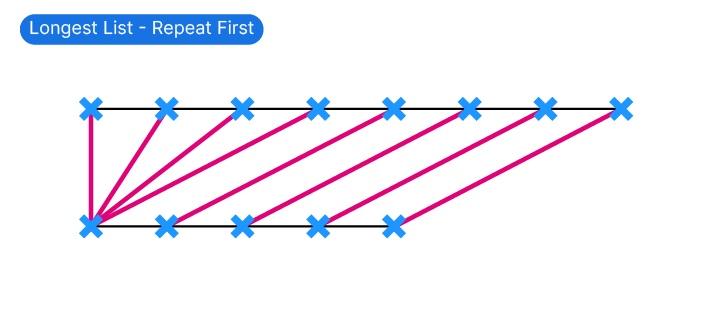
Repeat First
Repeat First duplicates the first item in the shorter list, and then matches the remaining items.
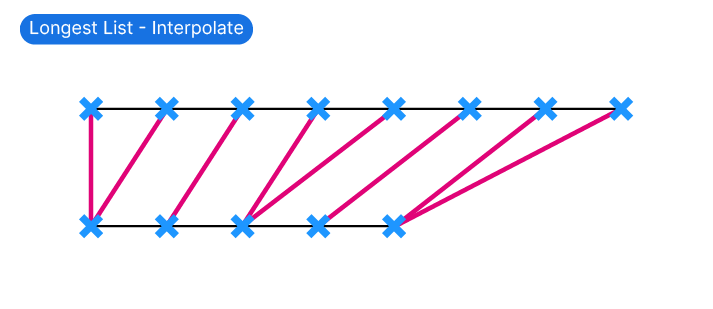
Interpolate
This is an interesting one: Interpolate will try to space out the shorter list so the difference in items is spread out equally.
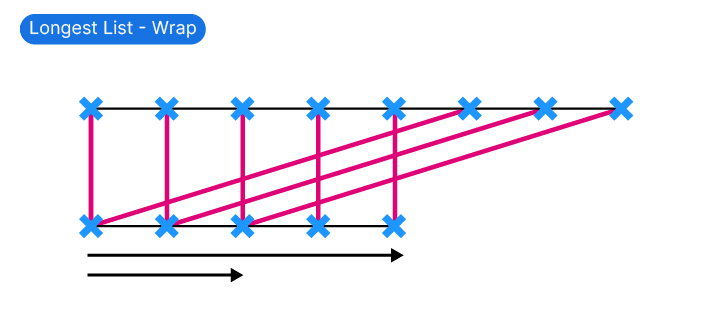
Wrap
The Wrap option completes the pairing until the shorter list runs out of items, then restarts the shorter list from the beginning.
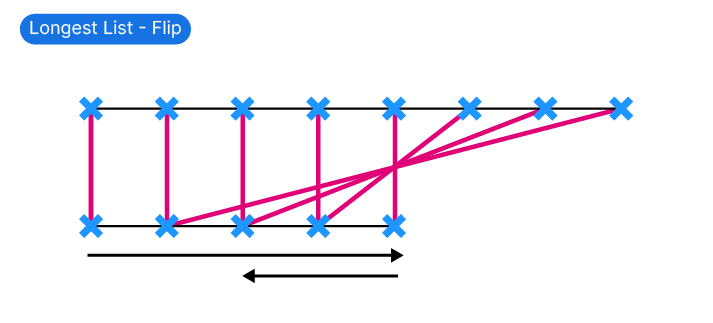
Flip
The Flip option completes the normal pairing, and then reverses the shorter list.
Shortest List and its Options
The Shortest List approach prioritizes the shorter list, and ignores the items of the longer list that don’t have a partner-item. This approach tries to eliminate the problem of ‘overlapping’ data that we see in the Longest List approach.
Here are the Shortest List modes:
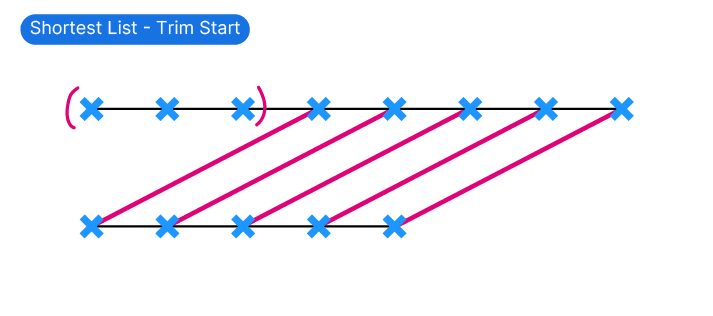
Trim Start
The Trim Start mode will match the items in the two lists from the end: the items are paired starting from the last and the remaining items are ignored, or trimmed.
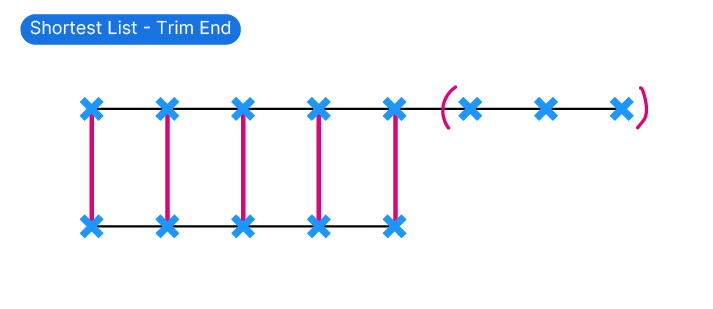
Trim End
The more natural Trim End matches items across the list linearly until one of them runs out, and then stops. I find this to be one of the most helpful data matching types, as it leads to predictable results.
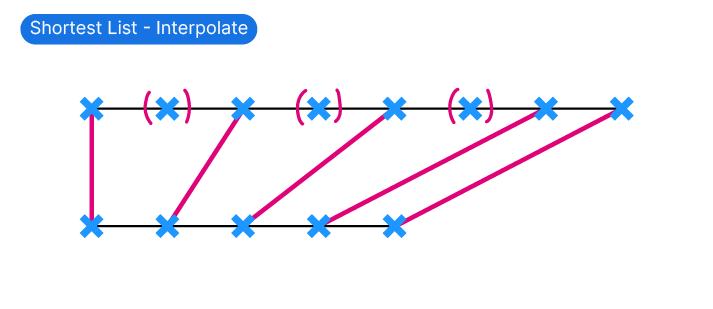
Interpolate
The Interpolate option of the Shortest List component tries to spread out the matching pairs over the longer list, removing the items in-between.
Cross-Reference with Application Example
An additional way of dealing with two lists, whether they have different lengths or not, is to cross-reference every single item. This means that every item of one list is connected or paired with every item of the other. I recommend to use this mode with caution – the number of resulting pairs can quickly escalate quickly and freeze or crash Grasshopper.
Holistic
There are a number options for the Cross-Reference component, but I’ve never really seen any use for any besides the default mode called ‘Holistic‘, displayed below.
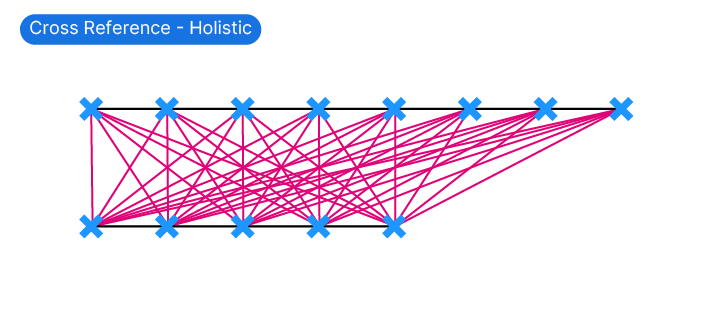
Now you may wonder why on earth one would ever need to cross-reference every item?
Application example
Let’s say we want to create a grid of points using x and y values. If we connect two number series with numbers ranging from 0 to 9 to the x and y inputs, we’ll get the result shown below.
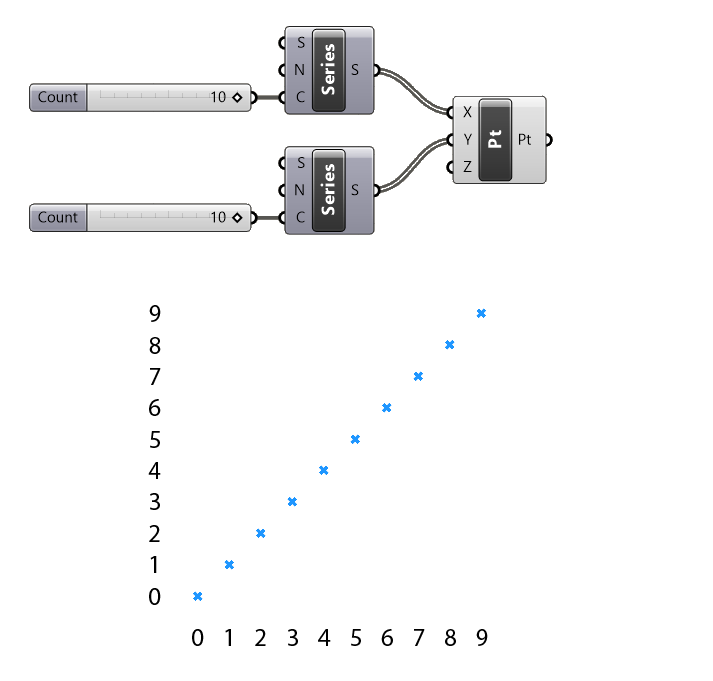
Since each item is paired with the item of the same index in the other list, all we get is a diagonal of points: (0,0), (1,1), (2,2) and so on.
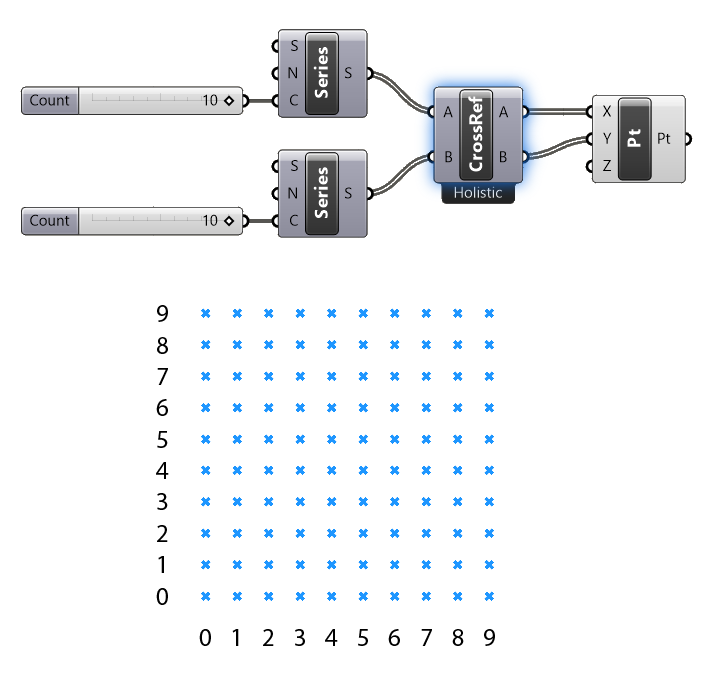
By adding the Cross-Reference component, we are pairing each item in List A with each item in List B, resulting in a full grid of points. Pretty neat, no?
Concluding Thoughts
Understanding the Longest List principle and the various data matching options in Grasshopper is essential for efficient parametric modeling. By mastering these techniques, you can ensure that your data streams are paired consistently and predictably, even when dealing with lists of different lengths.
I hope you’ve found this helpful!
Happy designing!